NLP-Fundamentals
N-gram
Problem statement
We want to design a autocorrect functionality, which requires knowing the probabilities of certain combinations of words.
Consider these phrases: “Table Mountain is beautiful,” “Table Mountain is huge.” They are familiar and make sense, but “Table Mountain is pangolin” and “Table Mountain is midnight” seem completely wrong. You may have heard the first phrases but never the others.
This suggests that there is a natural way to determine these probabilities: analyze collections of text and observe how words are actually used. The foundational principle for this approach was articulated decades ago by the British linguist John Rupert Firth, who famously stated, "you shall know a word by the company it keeps"
Intro
An n-gram is a sequence of n words that appear together in text. By counting how often different n-grams occur in large amounts of text, you can build a simple yet effective way to capture patterns of language.
N-grams works by statistically analyzing the co-occurence of words.
For example, if a model sees "jollof rice" hundreds of time in a dataset, then , which is the probability of the word "rice" immediately following given "jollof" is present, will be very high.
If you want the probability of word B following context A, you just count how often you see A and B together, and divide that by how often you see context A all by itself, which is the formula for conditional probability:
When it comes to n-grams, the probability of a word is just the number of times it appears in the dataset divided by the number of words in the dataset. Here's an example:
NOTE
Some intuition
So if you're trying to predict what comes after New York, and your data shows New York City appears 300 times, but New York appears once, then the model will predict city with extremely high confidence.

- unigrams: When n=1.
- bigrams: When n=2
- trigrams: When n=3.
- context window: The words that serve as preceding context in an n-gram model.


Limitations
- small context window: a small context window and repetitive nature makes it a fundamental weakness for NLP
- data sparsity: as increases, the possible combinations of n-grams increases and the probability of a certain 4 or 5-word combination appearing will be near zero for almost all combinations, leading to the model being useless.
- Even for , about 99.95% of bigrams have a probability of 0, meaning they don't appear even once even in a dataset of 26,000,000 bigram possibilities.
- For any context A, the probability will be 0 for most tokens B.
NOTE
Because of these limitations, transformers are much better for predicting the next word, since a transformer trains enough to understand grammar rules and context.
Here are some other limitations:
- Small corpus size: The Africa Galore dataset is small, which limits the model's ability to extract meaningful patterns about language.
- Inability to handle words that do not appear in the dataset: If an n-gram model encounters a context sequence (n-gram) that is not found in the dataset, it is unable to estimate the probability of the next word and stops generating text.
- Predictability and repetitiveness: The model relies on frequency counts to generate words, making outputs repetitive. Since the dataset is small, it will likely generate the same text structure every time.
- Lack of contextual awareness: Since n-grams only consider the last words, they ignore long-range dependencies. For instance, for the prompt “Jide was hungry, so she went looking for”, a trigram model will predict the next word based on “looking for” but will not retain the more important broader context of Jide being hungry. Moreover, the model sometimes misgenders Jide and uses "he" to refer to her.
Building an N-gram model
To build an n-gram language model, you need to determine the counts of all n-grams and (n-1)-grams so you can find all the conditional probabilities.
- Determine value of .
- Tokenize text into n-grams
- Create a dictionary where the keys are the context, which have a length of tokens, and the values are a frequency dictionary of the next token.
- Loop through the dictionary, and for each context key, calculate the probability of the n-gram for a certain next token by dividing the count of the next token over the total of the frequency dictionary. Repeat for all possible next tokens based on the context (frequency of next token is greater than 0).
For example, if the dataset consists of the two sentences "Table Mountain is tall." and "Table Mountain is beautiful." then the function called with
n = 3should return:{
"Table Mountain": Counter({"is": 2}),
"Mountain is": Counter({"tall": 1, "beautiful": 1})
}
# space tokenizer
def space_tokenize(text: str) -> list[str]:
"""
space tokenizer, splits text on a space
"""
tokens = text.split(" ")
return tokens
# generate n grams
def generate_ngrams(text: str, n: int) -> list[tuple[str]]:
"""Generates n-grams from a given text.
Args:
text: The input text string.
n: The size of the n-grams (e.g., 2 for bigrams, 3 for trigrams).
Returns:
A list of n-grams, each represented as a list of tokens.
"""
# Tokenize text.
tokens = space_tokenize(text)
# Construct the list of n-grams.
ngrams = []
# Add your code here.
for i in range(len(tokens) - n + 1):
ngrams.append(tuple(tokens[i:i+n]))
return ngrams
# generates dictionary of context -> next token
def get_ngram_counts(dataset: list[str], n: int) -> dict[str, Counter]:
"""Computes the n-gram counts from a dataset.
This function takes a list of text strings (paragraphs or sentences) as
input, constructs n-grams from each text, and creates a dictionary where:
* Keys represent n-1 token long contexts `context`.
* Values are a Counter object `counts` such that `counts[next_token]` is the
count of `next_token` following `context`.
Args:
dataset: The list of text strings in the dataset.
n: The size of the n-grams to generate (e.g., 2 for bigrams, 3 for
trigrams).
Returns:
A dictionary where keys are (n-1)-token contexts and values are Counter
objects storing the counts of each next token for that context.
"""
# Define the dictionary as a defaultdict that is automatically initialized
# with an empty Counter object. This allows you to access and set the value
# of ngram_counts[context][next_token] without initializing
# ngram_counts[context] or ngram_counts[context][next_token] first.
# Reference
# https://docs.python.org/3/library/collections.html#collections.Counter and
# https://docs.python.org/3/library/collections.html#collections.defaultdict
# for more information on how to use defaultdict and Counter types.
ngram_counts = defaultdict(Counter)
for paragraph in dataset:
# Add your code here.
n_grams = generate_ngrams(paragraph, n)
for ngram in n_grams:
context = " ".join(ngram[:-1])
next_token = ngram[-1]
ngram_counts[context][next_token] += 1
return dict(ngram_counts)
def build_ngram_model(
dataset: list[str],
n: int
) -> dict[str, dict[str, float]]:
"""Builds an n-gram language model.
This function takes a list of text strings (paragraphs or sentences) as
input, generates n-grams from each text using the function get_ngram_counts
and converts them into probabilities. The resulting model is a dictionary,
where keys are (n-1)-token contexts and values are dictionaries mapping
possible next tokens to their conditional probabilities given the context.
Args:
dataset: A list of text strings representing the dataset.
n: The size of the n-grams (e.g., 2 for a bigram model).
Returns:
A dictionary representing the n-gram language model, where keys are
(n-1)-tokens contexts and values are dictionaries mapping possible next
tokens to their conditional probabilities.
"""
# A dictionary to store P(B | A).
# ngram_model[context][token] should store P(token | context).
ngram_model = {}
# Use the ngram_counts as computed by the get_ngram_counts function.
ngram_counts = get_ngram_counts(dataset, n)
# Loop through the possible contexts. `context` is a string
# and `next_tokens` is a dictionary mapping possible next tokens to their
# counts of following `context`.
for context, next_tokens in ngram_counts.items():
# Compute Count(A) and P(B | A) here.
# Add your code here.
ngram_model[context] = {}
for token, count in next_tokens.items():
ngram_model[context][token] = count / next_tokens.total()
return ngram_model
Next-word prediction
- Create the dictionary mapping the token context to its conditional distribution given the context.
- Given a random combination of tokens, generate words by sampling from the conditional distribution, given that combination of tokens actually exists in our dictionary. You should notice that next tokens with the highest probability will be chosen more often.
- Once a token is chosen/generated, slide the window to leave out the first token and only include the last tokens as context for the next generation. Repeat this step until you generate as many words as you want.
WARNING
While it intuitively seems that a larger context (greater 𝑛) would lead to better quality output by capturing more long-range dependencies in language, it quickly runs into the problem of data sparsity since most n-grams will never be observed in the dataset.
def generate_next_n_tokens(
n: int,
ngram_model: dict[str, dict[str, float]],
prompt: str,
num_tokens_to_generate: int,
) -> str:
"""Generates `num_tokens_to_generate` tokens following a given prompt using
an n-gram language model.
This function takes an n-gram model and uses it to predict the most
likely next token for the given prompt. The generation process
continues iteratively, appending predicted tokens to the prompt until the
desired number of tokens is generated or a context is
encountered for which the model has no predictions.
Args:
n: The size of the n-grams to use (e.g., 2 for a bigram model).
ngram_model: A dictionary representing the n-gram language model.
prompt: The starting text prompt for generating the next tokens.
num_tokens_to_generate: The number of words to generate following
the prompt.
Returns:
A string containing the original prompt followed by the generated
tokens. If no valid continuation is found for a given context, the
function will return the text generated up to that point and print a
message indicating that no continuation could be found.
"""
# Split prompt into individual tokens.
generated_words = space_tokenize(prompt)
for _ in range(num_tokens_to_generate):
# Get last (n-1) tokens as context.
context = generated_words[-(n - 1):]
context = " ".join(context)
if context in ngram_model:
# Sample next word based on probabilities.
next_word = random.choices(
list(ngram_model[context].keys()),
weights=ngram_model[context].values()
)[0]
generated_words.append(next_word)
else:
print(
"⚠️ No valid continuation found. Change the prompt or"
" try sampling another continuation.\n"
)
break
return " ".join(generated_words)
Custom class
class NLP_utils():
@staticmethod
def space_tokenize(text: str) -> list[str]:
tokens = text.split(" ")
return tokens
class N_grams():
ngram_model: dict[str, dict[str, float]]
def __init__(self, n : int, dataset: list[str]) -> None:
self.n = n
self.dataset = dataset
self.build_ngram_model()
def generate_ngrams(self, text: str) -> list[tuple[str]]:
"""Generates n-grams from a given text.
Args:
text: The input text string.
n: The size of the n-grams (e.g., 2 for bigrams, 3 for trigrams).
Returns:
A list of n-grams, each represented as a list of tokens.
"""
# Tokenize text.
tokens = NLP_utils.space_tokenize(text)
# Construct the list of n-grams.
ngrams = []
# Add your code here.
n = self.n
for i in range(len(tokens) - n + 1):
ngrams.append(tuple(tokens[i:i+n]))
return ngrams
def get_ngram_counts(self) -> dict[str, Counter]:
"""Computes the n-gram counts from a dataset.
This function takes a list of text strings (paragraphs or sentences) as
input, constructs n-grams from each text, and creates a dictionary where:
* Keys represent n-1 token long contexts `context`.
* Values are a Counter object `counts` such that `counts[next_token]` is the
count of `next_token` following `context`.
Args:
dataset: The list of text strings in the dataset.
n: The size of the n-grams to generate (e.g., 2 for bigrams, 3 for
trigrams).
Returns:
A dictionary where keys are (n-1)-token contexts and values are Counter
objects storing the counts of each next token for that context.
"""
ngram_counts = defaultdict(Counter)
n = self.n
for paragraph in self.dataset:
# Add your code here.
n_grams = self.generate_ngrams(paragraph, n)
for ngram in n_grams:
context = " ".join(ngram[:-1])
next_token = ngram[-1]
ngram_counts[context][next_token] += 1
return dict(ngram_counts)
def generate_next_n_tokens_greedy_sampling(
self,
prompt: str,
num_tokens_to_generate: int,
) -> str:
"""Generates `num_tokens_to_generate` tokens following a given prompt using
an n-gram language model.
This function takes an n-gram model and uses it to predict the most
likely next token for the given prompt. The generation process
continues iteratively, appending predicted tokens to the prompt until the
desired number of tokens is generated or a context is
encountered for which the model has no predictions.
Args:
n: The size of the n-grams to use (e.g., 2 for a bigram model).
ngram_model: A dictionary representing the n-gram language model.
prompt: The starting text prompt for generating the next tokens.
num_tokens_to_generate: The number of words to generate following
the prompt.
Returns:
A string containing the original prompt followed by the generated
tokens. If no valid continuation is found for a given context, the
function will return the text generated up to that point and print a
message indicating that no continuation could be found.
"""
# Split prompt into individual tokens.
generated_words = NLP_utils.space_tokenize(prompt)
n = self.n
for _ in range(num_tokens_to_generate):
# Get last (n-1) tokens as context.
context = generated_words[-(n - 1):]
context = " ".join(context)
if context in self.ngram_model:
# Choose next word via MAP estimate (highest probability)
next_word_index = list(self.ngram_model[context].values()).index(max(self.ngram_model[context].values()))
next_word = list(self.ngram_model[context].keys())[next_word_index]
generated_words.append(next_word)
else:
print(
"⚠️ No valid continuation found. Change the prompt or"
" try sampling another continuation.\n"
)
break
return " ".join(generated_words)
def build_ngram_model(
self,
) -> dict[str, dict[str, float]]:
"""Builds an n-gram language model.
This function takes a list of text strings (paragraphs or sentences) as
input, generates n-grams from each text using the function get_ngram_counts
and converts them into probabilities. The resulting model is a dictionary,
where keys are (n-1)-token contexts and values are dictionaries mapping
possible next tokens to their conditional probabilities given the context.
Args:
dataset: A list of text strings representing the dataset.
n: The size of the n-grams (e.g., 2 for a bigram model).
Returns:
A dictionary representing the n-gram language model, where keys are
(n-1)-tokens contexts and values are dictionaries mapping possible next
tokens to their conditional probabilities.
"""
# A dictionary to store P(B | A).
# ngram_model[context][token] should store P(token | context).
ngram_model = {}
n = self.n
# Use the ngram_counts as computed by the get_ngram_counts function.
ngram_counts = get_ngram_counts(self.dataset, n)
# Loop through the possible contexts. `context` is a string
# and `next_tokens` is a dictionary mapping possible next tokens to their
# counts of following `context`.
for context, next_tokens in ngram_counts.items():
# Compute Count(A) and P(B | A) here.
# Add your code here.
ngram_model[context] = {}
for token, count in next_tokens.items():
ngram_model[context][token] = count / next_tokens.total()
self.ngram_model = ngram_model
def generate_next_n_tokens(
self,
prompt: str,
num_tokens_to_generate: int,
) -> str:
"""Generates `num_tokens_to_generate` tokens following a given prompt using
an n-gram language model.
This function takes an n-gram model and uses it to predict the most
likely next token for the given prompt. The generation process
continues iteratively, appending predicted tokens to the prompt until the
desired number of tokens is generated or a context is
encountered for which the model has no predictions.
Args:
n: The size of the n-grams to use (e.g., 2 for a bigram model).
ngram_model: A dictionary representing the n-gram language model.
prompt: The starting text prompt for generating the next tokens.
num_tokens_to_generate: The number of words to generate following
the prompt.
Returns:
A string containing the original prompt followed by the generated
tokens. If no valid continuation is found for a given context, the
function will return the text generated up to that point and print a
message indicating that no continuation could be found.
"""
# Split prompt into individual tokens.
generated_words = NLP_utils.space_tokenize(prompt)
n = self.n
for _ in range(num_tokens_to_generate):
# Get last (n-1) tokens as context.
context = generated_words[-(n - 1):]
context = " ".join(context)
if context in self.ngram_model:
# Sample next word based on probabilities.
next_word = random.choices(
list(self.ngram_model[context].keys()),
weights=self.ngram_model[context].values()
)[0]
generated_words.append(next_word)
else:
print(
"⚠️ No valid continuation found. Change the prompt or"
" try sampling another continuation.\n"
)
break
return " ".join(generated_words)
Tokenization
A tokenizer is a way to split up text into groups of tokens.
Simple tokenizers
- space tokenizers: splits text into individual words by splitting on space characters.
Word Embeddings
Why word embeddings
motivation
We need a way to semantically represent words in a language so that a computer can "understand" a language mathematically.
This means we have to convert words into numbers, which is something a computer can understand. We call these word to number conversions as embeddings, and they must have these properties in order to be useful.
Finding a word embedding is the idea of somehow representing the meaning of word with a vector of numbers.
vector similarity
Word embedding similarity is embodied by subtracting vectors. Here is an example:
A neural network that learns word embeddings would encode difference between words as a direction, like how the difference between a man and woman is the same difference as the difference between a king and queen, which is gender.
Therefore you could encode the word “queen” like so:
Another cool effect is that this works the exact same as analogies: “man:woman as king:queen”.
Therefore there are two desirable properties of good word embeddings:
- Words representing similar concepts will be closer together in the vector space.
- Words representing different concepts will be farther away and have a lower similarity score.
cosine similarity
Cosine similarity uses the property of the dot product to measure how close two vectors are together in space.
NOTE
We use cosine similarity to measure how similar two word embeddings are because that metric works the same no matter the dimensionality.
main goal of language models
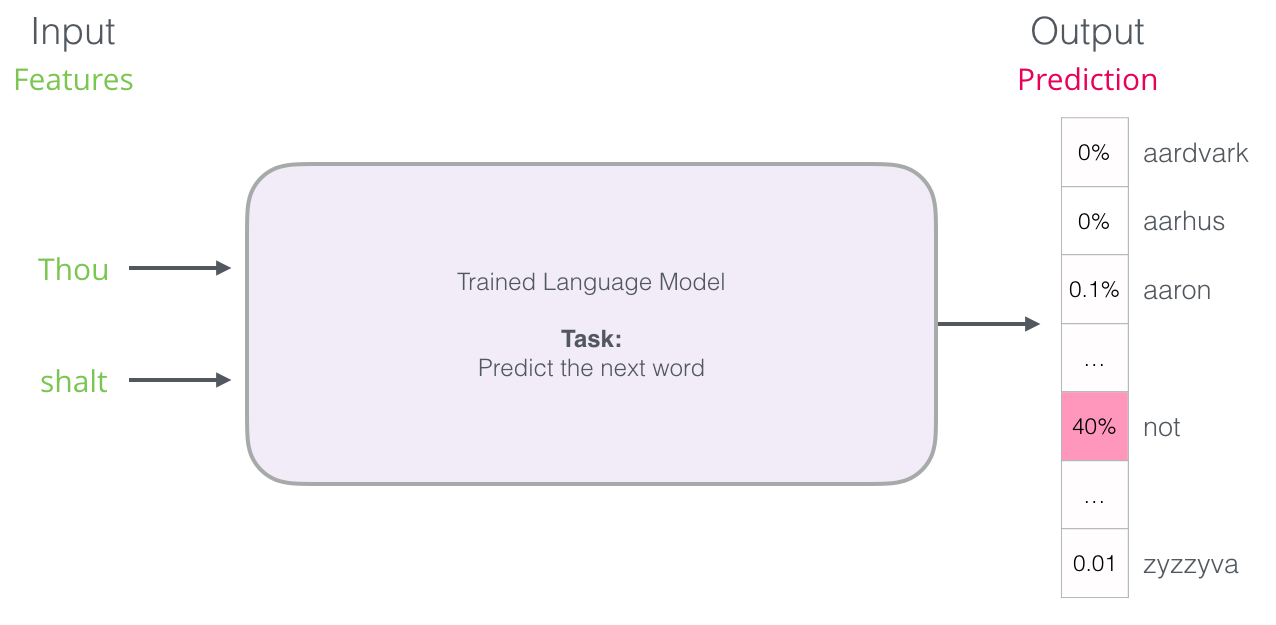
The purpose of language models is based on a word embedding or groups of them, to predict the next word. It does this by outputting a probability distribution where the random variable ranges over all vocabulary words.
Visualizing word embeddings
Good word embeddings will have similar words be closer together in the vector space and more different words farther apart. To verify this is the case however, we need some way of projecting a multi-dimensional word embedding into two dimensions so we plot them on a cartesian coordinate space.
We can do this with TSNE
Previous approaches
We want to numerically represent words and sentences somehow so we can train a system on textual info. Here are two existing techniques that are inferior to word embeddings:
- bag of words: Simply encoding frequency of words within a sentence. This does not encode grammar correctly, making it useless for slightly complex sentences.
- one hot encoding: Doesn’t take into account similarity between words.
Cons of one-hot encoding
Similar vectors would be words that mean similar things - that's the essence of what makes for a good word embedding.
However, each one-hot encoded vocab embedding is orthogonal to each other (have a dot product of 0 thus similarity of 0), meaning they all have the exact same similarity.

Embedding matrix representation
embedding matrix representation
We represent the matrix of word embeddings as a matrix , where is the dimensionality of the embedding and is the vocabulary length - as in all the words you’re trying to embed.
- : denotes the one-hot encoded vector of the th word in the vocab
- : denotes the embedding of the th word in the vocab
The embedding matrix is useful because it lets us translate from one-hot encoded vectors to word embedding vectors:
Word embedding approaches overview
NNLM
NNLMs try to deal with one-hot encoded words as word embeddings by taking the neural network approach to train on those one-hot encoded vectors.

Therefore the neural network architecture is as follows:
- input layer: A (embedding dimensionality) long one-hot vector encoding the “context” word for a unigram architecture, or dimensional one-hot vector for an n-gram architecture where you concatenate one-hot encoded vectors together.
- first layer: A dense layer, which should be larger than the input layer as to not lose information.
- output layer: A softmax layer of elements built to predict the target word from the context, where if element indexed has the largest probability in the distribution, then is the output.
However, there are three main drawbacks to this approach:
- computationally expensive: With a vocab size of just 10,000, even a single hidden layer could mean hundreds of millions of parameters.
- order is not encoded: All one-hot encoded vectors are fed in at once to a dense layer, meaning order is not encoded at all.
- training time is slow
Word2Vec
Glove
Transformers
The same word can mean different things depending on the sentence context, like "blue" for the color or feeling sad. Transformers solve this problem via self-attention, meaning they understand context as opposed to simple Word2Vec.
Word2Vec
Token Semantics
We often remove stop words like “is”, “or”, “both” because they don’t have a lot of semantic meaning and are context-specific. There is no point creating embeddings for those.
Transformers
Self-attention
Motivation
Word embeddings cannot take context into account, which is important to truly master a language.
Take the word "Bank". In a static embedding space, "Bank" only has one coordinate. But consider these two sentences:
- "I sat by the river bank."
- "I deposited money in the bank."
Self-attention via transformers solves this problem by creating a mathematical method to give a word a contextualized vector representation that changes based on the context of the surrounding words in a sentence.
For example, self-attention should accomplish the following:
- In sentence 1, "bank" should pay attention to "river"
- In sentence 2, "bank" should pay attention to "money".
Matrix Formalism
We use three matrices in self-attention: Queries (Q), Keys (K), and Values (V)
Think of it like a database:
- Query (Q): What you type into the search bar (e.g., "calculus tutorial").
- This is what a word is looking for.
- Key (K): The video title/tags (e.g., "Math 101: Derivatives").
- This is what a word offers to others.
- Value (V): The actual video content you watch.
- This is the underlying meaning the word provides if it's a good match.
In a Transformer, every single word in a sentence generates its own Query, Key, and Value vectors by multiplying its original word embedding by three learned weight matrices () which are learned via backpropagation.
The first step is to gather the three matrices you need: , , and , which are derived from multiplying each input word embedding by the associated weights:
- : the positionally-encoded version of a word embedding. Has elements, which is the embedding size.
- : the key vector for the word .
- : the query vector for the word .
- : the value vector for the word .
NOTE
Each weight matrix is dimensional, which will result in a linear transformation of the positionally-encoded embedding (it will retain the same size).
You can then form , , and by just stacking each generated on top of each other in rows.
Here's the full formula:
- (The Dot Product): We take the dot product of every word's Query with every other word's Key. As we learned in Step 1, the dot product measures similarity. If the Query of "bank" aligns well with the Key of "river", the resulting dot product is a large positive number!
- (The Scaling Factor): We divide by the square root of the dimension of the key vectors. This is a neat calculus/probability trick: if dimensions get too high, dot products explode in magnitude, which pushes the softmax function into regions with tiny gradients (vanishing gradients). Scaling fixes this.
- : We apply the softmax function to turn these raw similarity scores into a probability distribution (weights that sum up to 1)
Multi-head attention
But language is incredibly complex. Consider the word "saw" in: "I saw the man with the saw." A word might need to track several different types of relationships at the same time:
- Who is doing the action? (Subject-Verb)
- What is the object?
- What is the tense? (Past/Present)
If we only have one set of Q, K, V matrices (one "attention head"), the model has to average all these relationships together, muddying the math.
The Solution: We create multiple "Heads"! Instead of one , we initialize, say, 8 different sets of these matrices. We project our word embeddings into 8 smaller, distinct mathematical subspaces.
- Head 1 might learn to pay attention to grammar.
- Head 2 might learn to pay attention to rhyming words.
- Head 8 might track emotional tone.
We run the Scaled Dot-Product Attention equation on all 8 heads in parallel, concatenate their resulting matrices, and multiply them by a final output weight matrix to get our new, incredibly rich, contextualized word embeddings.