Command line and Node basics
Command line arguments
You can get all the command line arguments you type in from the process.argv array. However, this stores all the command line arguments.
node index.js is itself two command line arguments:
- The first argument will always be the path to the node binary
- The second argument will always be the filepath of the file node is running
- Any additional arguments are ones you pass in.
So to parse any arguments you pass in, you have to start looking from the 2nd element onward in process.argv.
File System
Filepath manipulation
// Some important paths
process.cwd(); // Absolute path of the current working directory.
__filename; // Absolute path of the file that holds the current code.
__dirname; // Absolute path of the directory that holds __filename.
os.homedir(); // The user's home directory.
const path = require("path");
path.sep; // Either "/" or "\" depending on your OS
// The path module has simple parsing functions
let p = "src/pkg/test.js"; // An example path
path.basename(p); // => "test.js"
path.extname(p); // => ".js"
path.dirname(p); // => "src/pkg"
path.basename(path.dirname(p)); // => "pkg"
path.dirname(path.dirname(p)); // => "src"
// normalize() cleans up paths:
path.normalize("a/b/c/../d/"); // => "a/b/d/": handles ../ segments
path.normalize("a/./b"); // => "a/b": strips "./" segments
path.normalize("//a//b//"); // => "/a/b/": removes duplicate /
// join() combines path segments, adding separators, then normalizes
path.join("src", "pkg", "t.js"); // => "src/pkg/t.js"
// resolve() takes one or more path segments and returns an absolute
// path. It starts with the last argument and works backward, stopping
// when it has built an absolute path or resolving against process.cwd().
path.resolve(); // => process.cwd()
path.resolve("t.js"); // => path.join(process.cwd(), "t.js")
path.resolve("/tmp", "t.js"); // => "/tmp/t.js"
path.resolve("/a", "/b", "t.js"); // => "/b/t.js"
Important paths
process.cwd(): Absolute path of the current working directory.__filename: Absolute path of the file that holds the current code. Right now this is the absolut path of07-command-line.md__dirname: Absolute path of the directory that the current file lives inos.homedir(): The user's home directory.path.sep: Either "/" or "" depending on your OS, used for path separators.
Path methods
path.basename(filepath): Returns the basename (filename) of the path, like json.txtpath.extname(filepath): Returns the extension of the path, like.txtpath.dirname(filepath): Returns the directory name of the path, like./src/pkgpath.resolve(filepath): Returns the absolute path of the given filepath
Get file info
The fs.statSync() method takes in a filepath and returns information about that file or folder, returning a stats object. The stats object has the following properties and methods:
stats.isFile(): Returns true if the path is a filestats.isDirectory(): Returns true if the path is a directorystats.size: Returns the size of the file in bytes
const fs = require("fs");
let stats = fs.statSync("book/ch15.md");
stats.isFile(); // => true: this is an ordinary file
stats.isDirectory(); // => false: it is not a directory
stats.size; // file size in bytes
__dirname in es6 modules
When using es6 modules in node by change the "type" key in the package json to "module", you no longer have access to the __dirname variable. To get the current directory, instead you have to do code like this:
import { fileURLToPath } from "url";
import { dirname, join } from "path";
// import.meta.url is the URL version of the filepath of the current file
const currentFileURL = import.meta.url;
// 1. convert import.meta.url to a static filepath
// 2. get the directory path of the directory that houses that filepath
const currentDir = dirname(fileURLToPath(currentFileURL));
// you now have access to the current directory as you please
const DB_FILE = join(currentDir, "db.json");
Filesystem manager
Creating executable files
By using the fs.writeFile() function, you can pass in an object of options, specifically the mode option and pass in an octal permission number.
The example below creates a functioning bash script (yes, it is necessary to add code besides the shebang).
export async function createBashFile(filepath: string) {
await fs.writeFile(filepath, "#!/bin/bash\necho 'hello'", {
mode: 0o777,
});
}
Adding to path
import fs from "node:fs/promises";
import os from "node:os";
import path from "node:path";
import process from "node:process";
async function getShellProfileContents() {
// Detect the user's shell and profile file
const shell = process.env.SHELL || "";
let profileFile = "";
if (shell.includes("zsh")) {
profileFile = path.join(os.homedir(), ".zshrc");
} else if (shell.includes("bash")) {
profileFile = path.join(os.homedir(), ".bashrc");
} else {
// fallback
profileFile = path.join(os.homedir(), ".profile");
}
// Check if already present
let content = "";
try {
content = await fs.readFile(profileFile, { encoding: "utf-8" });
} catch (e) {
console.error(e);
// File may not exist, will be created
}
return { profileFile, content };
}
export async function addToPath(folderPath: string) {
const { profileFile, content } = await getShellProfileContents();
const exportLine = `export PATH="$PATH:${folderPath}"\n`;
if (content.includes(exportLine.trim())) {
console.log(`${folderPath} already in your PATH.`);
return;
}
// Append to profile
await fs.appendFile(profileFile, exportLine);
console.log(`Added ${folderPath} to your PATH in ${profileFile}.`);
console.log(`Please run: source ${profileFile} or restart your terminal.`);
}
export async function removeFromPath(folderPath: string) {
const { profileFile, content } = await getShellProfileContents();
const exportLine = `export PATH="$PATH:${folderPath}"\n`;
if (content.includes(exportLine.trim())) {
const newContent = content.replace(exportLine, "");
await fs.writeFile(profileFile, newContent);
console.log(`Removed ${folderPath} from your PATH in ${profileFile}.`);
console.log(`Please run: source ${profileFile} or restart your terminal.`);
} else {
console.log(`${folderPath} not found in your PATH.`);
}
}
Running CLI commands in Node
The child_process module in node allows you to run command line tools from within your nodeJS program, like cd, ls, and much more.
You can import it like so:
import * as child_process from "child_process";
ExecSync
The child_process.execSync(command, options) method takes in a string command as its first argument, an an object of options as its second.
This method invokes a unix shell and runs the command in that shell, returning the standard output of the command as a string. If the command fails, it throws an error.
import * as child_process from "child_process";
async function runLinuxCommandLevel1() {
try {
// run the ls -l . command and store stdout in the output variable
let output = child_process.execSync("ls -l .", {
encoding: "utf8",
});
console.log(output);
} catch (err) {
// if the command fails, catch the error and log it
console.log(err);
}
}
ExecFileSync
For a more performant way of running linux commands, we can use the child_process.execFileSync(command, args, options) method. This method takes in a command as its first argument, an array of arguments and options as its second, and an object of options as its third.
You can also execute scripts you wrote yourself with this.
- First argument: the file/script or command to run
- Second argument: a list of command line options to pass in
- Third argument: options like encoding
It's more perfomant because it doesn't spawn a shell, but instead runs the command directly.
async function runLinuxCommandLevel2() {
try {
let output = child_process.execFileSync("ls", ["-l", "."], {
encoding: "utf8",
});
console.log(output);
} catch (err) {
console.log(err);
}
}
Spawn
With the child_process.spawn() method, we can have a more asynchronous approach where we listen to the stdout and stderr streams from executing a command.
const commandListener = spawn(command, [option1, option2, ...], options)
Like the other methods, here are the arguments in order:
- First argument: the file/script or command to run
- Second argument: a list of command line options to pass in
- Third argument: options like encoding
const { spawn } = require("child_process");
// runs this command: identify -verbose bidengoeshard.png
const identify = spawn("identify", ["-verbose", "bidengoeshard.png"]);
// handles the stdout stream
identify.stdout.on("data", (data: string) => {
// prints out the output in the command line from running the identify command
console.log(`stdout:\n ${data}`);
});
// handles the stderr stream
identify.stderr.on("data", (data: string) => {
// prints out the error in the command line, if any, when running the identify command
console.log(`stderr:\n ${data}`);
});
identify.on("exit", (code: number) => {
console.log(`child process exited with code ${code}`);
});
Wrapper CLI class�
Here's a wrapper CLI class around all of that
import { spawnSync, spawn, execFile } from "node:child_process";
import path from "node:path";
import os from "node:os";
interface ProcessOptions {
cwd?: string;
quiet?: boolean;
detached?: boolean;
}
class LinuxError extends Error {
constructor(command: string, extraData?: string) {
super(`Running the '${command}' command caused this error`);
console.error(extraData);
}
}
export default class CLI {
static isLinux() {
const platform = os.platform();
return platform === "linux";
}
static isWindows() {
const platform = os.platform();
return platform === "win32";
}
static getAbsolutePath(filePath: string) {
return path.join(__dirname, path.normalize(filePath));
}
/**
*
* Synchronous linux command execution. Returns the stdout
*/
static linux_sync(command: string, args: string[] = []) {
try {
const { status, stdout, stderr } = spawnSync(command, args, {
encoding: "utf8",
});
if (stderr) {
throw new LinuxError(command, stderr);
}
return stdout;
} catch (e) {
console.error(e);
throw new LinuxError(command);
}
}
/**
* Asynchronous command execution for executable files
*
* @param filepath the path to the executable
* @param command any commands to pass to the executable
* @param options cli options
* @returns stdout or stderr
*/
static cmd(
filepath: string,
command: string,
options?: ProcessOptions
): Promise<string> {
const args = command
.match(/(?:[^\s"]+|"[^"]*")+/g)
?.map((arg) => arg.replace(/"/g, ""));
if (!args) {
throw new Error("Invalid command");
}
return new Promise((resolve, reject) => {
execFile(
filepath,
args,
{
maxBuffer: 500 * 1_000_000,
...options,
},
(error, stdout, stderr) => {
if (error) {
console.log(`Error executing ${path.basename(filepath)}:`, error);
reject(stderr);
} else {
resolve(stdout);
}
}
);
});
}
/**
* Asynchronous command execution for bash shell
*
* @param command the command to run
* @param options cli options
* @returns stdout or stderr
*/
static linux(command: string, options?: ProcessOptions): Promise<string> {
try {
// send back stderr and stdout
return new Promise((resolve, reject) => {
const child = spawn(command, {
shell: true,
...options,
});
let stdout = "";
let stderr = "";
child.stdout?.on("data", (data) => {
options?.quiet === false && console.log(data.toString());
stdout += data.toString();
});
child.stderr?.on("data", (data) => {
options?.quiet === false && console.log(data.toString());
stderr += data.toString();
});
child.on("close", (code) => {
if (code !== 0) {
reject(new LinuxError(command, stderr));
} else {
resolve(stdout);
}
});
});
} catch (e) {
throw new LinuxError(command);
}
}
}
Using 3rd party libraries: zx
Install like so:
npm i zx
npm i -D @types/fs-extra @types/node
Just like how you can do bun shell scripting with $, you can do the exact same thing with google's zx library, which uses tagged template literal functions and escapes and sanitizes all input.
import { $ } from 'zx';
await $`ls -la`;
const branch = await $`git branch --show-current`;
await $`mkdir -p ${branch}/src`;
$: tagged template literal function that runs shell commands asynchronously and returns aProcessOptionsobject$.sync: tagged template literal function that runs shell commands synchronously and returns aProcessOptionsobject
Here is what the ProcessOptions object that is returned looks like, and you can just print it out with the toString() implementation.
class ProcessOutput {
readonly stdout: string
readonly stderr: string
readonly signal: string
readonly exitCode: number
toString(): string // Combined stdout & stderr.
}
Not awaiting the promise
The $ async function doesn't return a normal promise. Rather it returns a wrapper aorund that promise called a ProcessPromise, which has extra utilities like seeing the duration of the promise, what stage it is in, and even getting data from the promise without outputting to the command line.
When you don't await the promise, you can do stuff with it:
const p = $`echo 'foo\nbar'`
await p.text() // foo\n\bar\n
await p.text('hex') // 666f6f0a0861720a
await p.buffer() // Buffer.from('foo\n\bar\n')
await p.lines() // ['foo', 'bar']
await $`echo '{"foo": "bar"}'`.json() // {foo: 'bar'}
You can even consume it in an async generator fashion with a for ... await loop:
const p = $`echo "Line1\nLine2\nLine3"`
for await (const line of p) {
console.log()
}
You can use them in a stream-like fashion:
await $`echo "Hello, stdout!"`
.pipe('/tmp/output.txt') // pipes stream output to a file
You can also pipe shell commands together:
const greeting = await $`printf "hello"`
.pipe($`awk '{printf $1", world!"}'`)
.pipe($`tr '[a-z]' '[A-Z]'`)
echo(greeting)
Advantages and niche features
The zx library offers a couple of niche yet appreciated features that improves DX greatly:
- No need to put anything like double quotes or single quotes, because anything interpolated with the tagged template literals
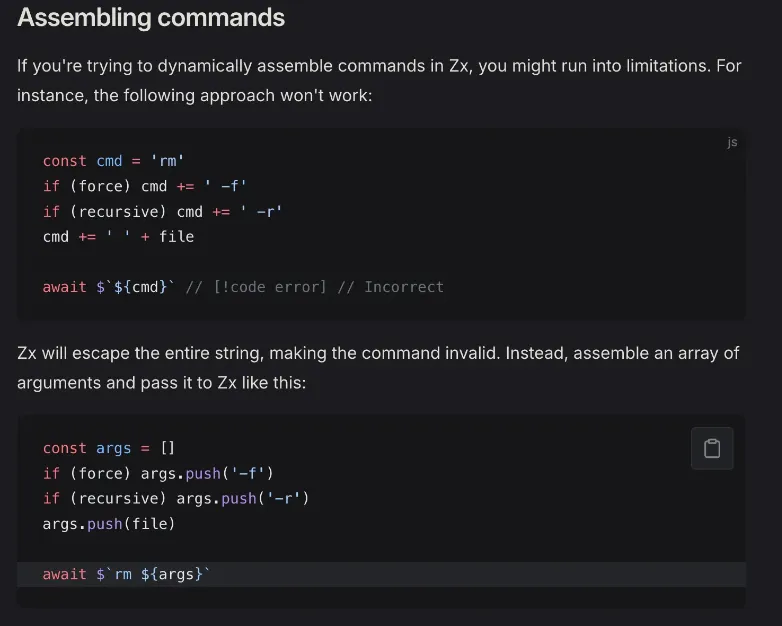
${...}is automatically parsed and put in single quotes. - You can pass in an array of flags instead of joining them with spaces.
const flags = [
'--oneline',
'--decorate',
'--color',
]
await $`git log ${flags}`
Since zx escapes everything by default, you can't use glob syntax. Instead, you have to use this glob() function:
const files = await glob('./**/*.md')
await $`ls ${files}`
Since zx escapes everything by default, you can't refer to the home directory with ~. Rather, you must get it programmatically through something like os.homedir()
await $`ls ${os.homedir()}/Downloads` // Correct